# Parametric vs Instance-based Model
# Parametric Model
is ideal when the problem can be solved through an equation with params, so the training data can be fit and those parameters derived using ML. Doesn't require storing the data once the parameters are derived.
Space efficient, slow queries
The more the number of parameters, the likely the model will overfit.
# Instance-based Model
is good for cases where the problem can't be really expressed through a set of parameters.
Fast training, ease to add new data
# Supervised Regression Learning
- Linear Regression (Parametric): Learning data is fitted to come up with parameters which are then used for prediction, hence Parametric.
- K-Nearest Neighbors (Instance-based): Learning data is preserved and consulted to make prediction, hence instance-based.
- Decision Trees: Stores a tree structure and when a prediction task comes in, it trickles down the nodes of the tree based on the conditions it satisfies until it finally reaches a leaf node where the outcome is.
- Decision Forest: Many decision trees taken together each one is queried to get an overall result.
# Problems with Regression
- Noisy and uncertain
- Challenging to estimate confidence
- Holding time, allocation
- Reinforcement learning can help navigate some of this
# KNN
- K=1 is when the model is most likely to overfit since the query corresponds to exactly one of the data points instead of taking an average of x neighbors.
- Normalize the data so all features with different value ranges are all treated as of equal importance.
# Testing
# Roll Forward Cross-Validation
Cross Validation is great but doesn't work quite well in financial data cause it provides a peek to the future due to the timeseries nature of data. In order to avoid it, we can use Roll forward cross validation which essentially is cross validation, but one where the train data is always before testing data.
# Backtesting
Accuracy of the model itself is not enough. Using the prediction and observing its progress in the market through backtesting is equally important.
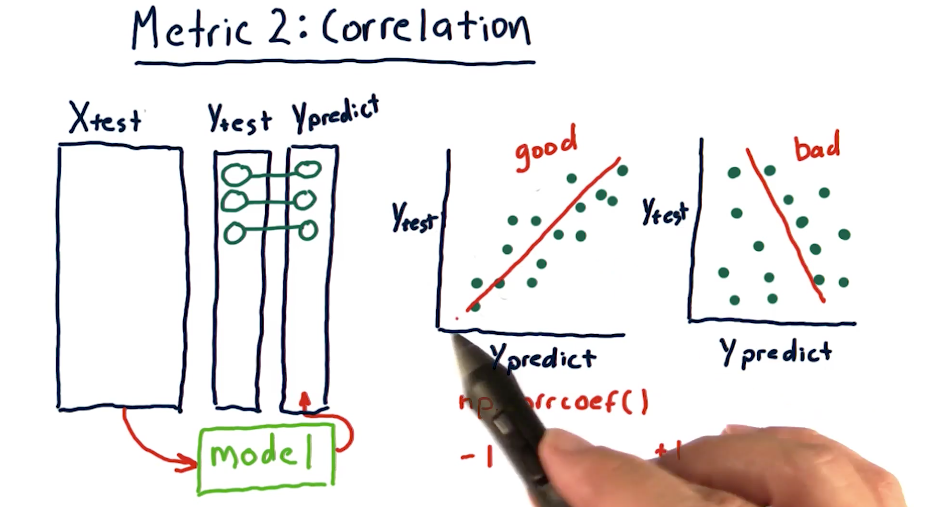
# Metrics to Assess Model
- RMSE Error
- Correlation
In most cases, when RMS error increases, correlation decreases. But we can't really be sure.
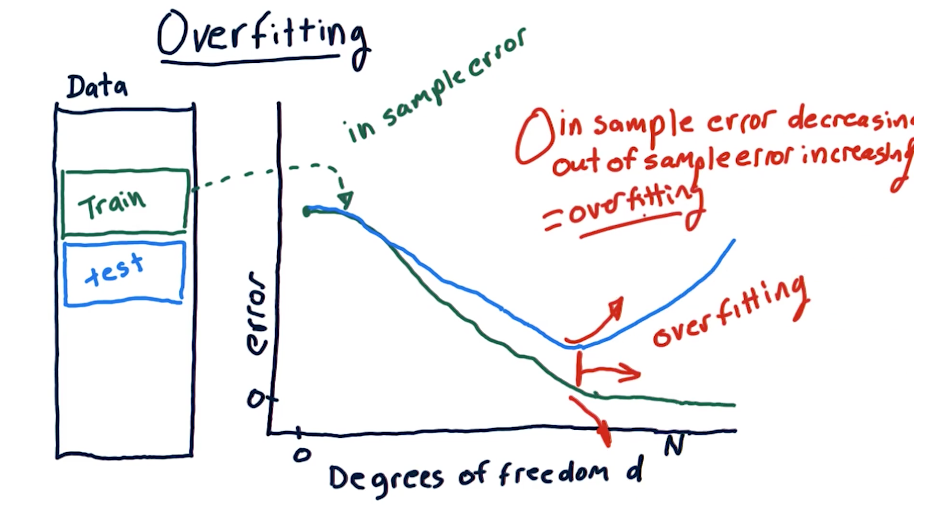
# Overfitting
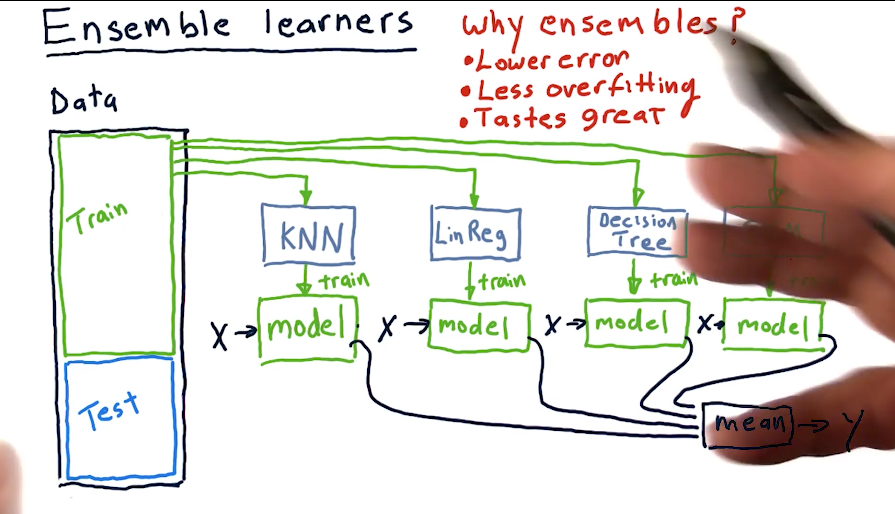
# Ensemble Learning
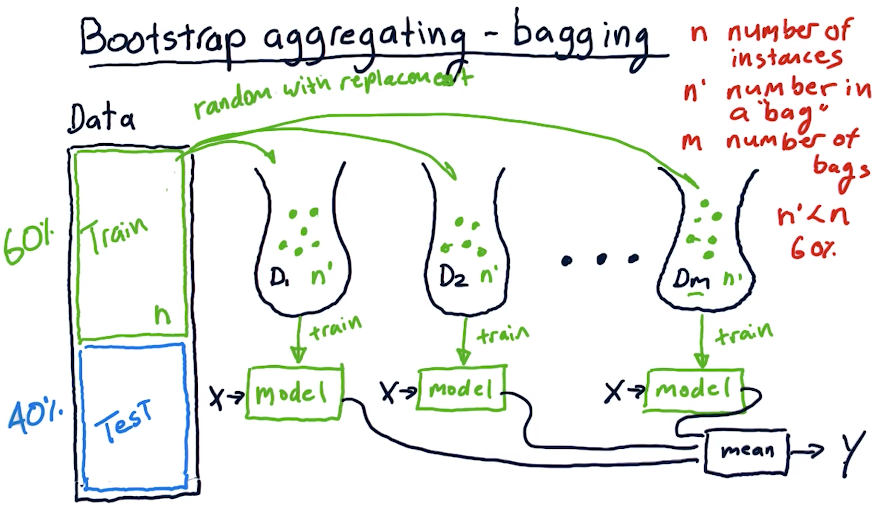
# Bagging - Bootstrap Aggregating
- Create different subsets of data from the training data by drawing bags of data at random with replacement. Each bag should have only about a 60% from the original set.
- Train multiple models each with a different bag of data
- When it is time to predict, predict using all models and take the mean of the results.
# Characteristics of Bagging
- Wraps for existing methods
- Reduces error
- Reduces overfitting
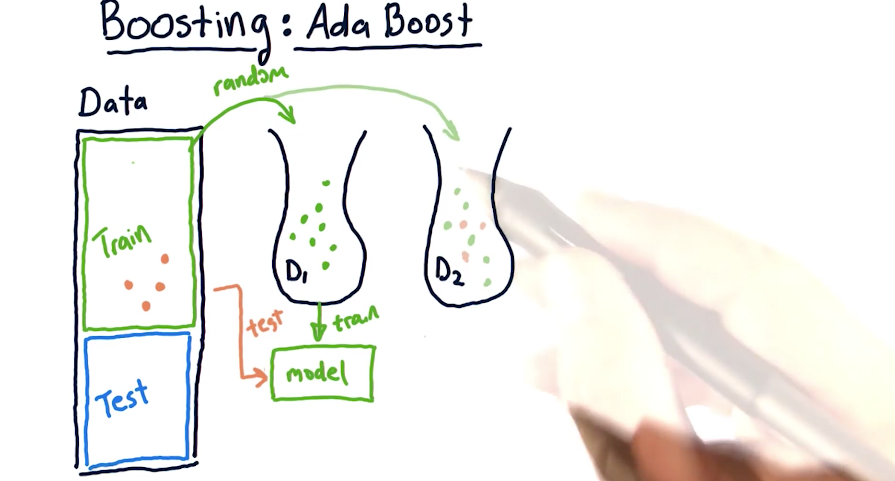
# Ada Boost
A variation of bagging in which while bagging, subsequent bags choose records which did poorly when testing the model (trained on the previous bag) on the entire set of training data. If not done right, likely to overfit than simple bagging.